Abstract
- 기존 연구에서와 달리 object detection을 회귀 문제로 구성. 이미지 전체를 한 번에 분석하여 바운딩 박스와 클래스 확률을 에측
- 전체 탐지 파이프라인이 하나의 뉴럴 네트워크 상에서 이루어지기 때문에 탐지 퍼포먼스의 최적화가 가능
- 초당 45 프레임의 속도로 객체 탐지가 가능함
- 조금 더 작은 모델인 Fast YOLO의 경우 155프레임의 속도로 객체 탐지가 가능
1. Introduction
- 기존 R-CNN과 같은 방식은 느리고 비효율적. 이는 모든 물체들이 독립적으로 학습되기 때문임.
- Object가 존재할 것으로 추정되는 곳에 잠재적 bounding box 생성
- classifier로 bounding box 분류
- 겹치는 bounding box를 제거하기 위한 후처리
- 해당 scene에 존재하는 다른 object들에 대한 box들 재평가

- YOLO의 단일 convolution 네트워크에서는 다중 물체들에 대한 multiple bounding box와 class 확률 계산을 동시에 진행한다.
- 다른 realtime system들의 두배 이상의 mAP(mean Average Precision)를 기록함
- precision: 모델이 true로 예측한 것들 중 실제 true인 비율
- in object detection: 모델이 검출한 obejct 중 ground truth object의 비율
- recall: 실제 true 라벨들 중 모델이 true로 예측한 비율
- in object detection: 전체 ground truth object들 모델이 검출에 성공한 object 비율
- precision: 모델이 true로 예측한 것들 중 실제 true인 비율
- IoU: 모델이 검출한 bounding box와 ground truth가 곂치는 부분의 비율. 특정 threshold를 넘긴 predict bounding box에 대해서 TP로 판단.
- PR Curve: confidence score에 대한 threshold 값이 변화함에 따른 Precision과 Recall의 변화량을 나타낸 그래프이다. object detection에서 confidence score는 IoU가 된다.
- AP: PR Curve의 밑 면적을 의미
- mAP: object detection은 여러개의 클래스가 존재하는데 mAP는 각 클래스들의 AP의 평균을 나타낸다.
- YOLO는 이미지를 global하게 보기 때문에 기존 Fast-RCNN과 같이 작은 패치 단위로 이미지를 보던 방법에 비해 절반 이하의 background error를 기록
- 물체의 일반화된 특성을 잘 파악하기 때문에 학습은 자연 이미지로, 테스트는 아트워크로 하여도 잘 작동하는 모습을 보여줌
- 작은 물체에 대해서는 여전히 detection을 어려워함
2. Unified Detection
- 이미지 전체의 feature를 통해서 bounding box를 예측하며 모든 클래스에 대한 bounding box를 즉각적으로 예측한다.
- 각 box는 $(x,y,w,h)$로 표현되며 각각 중심의 좌표와 너비, 높이를 표현한다.
- 인풋 이미지를 S x S의 grid cell로 나눈 후 물체의 중심이 grid cell에 포함되는 경우 해당 grid cell이 object detection을 진행한다.
- grid cell은 최대 $B$개의 bounding box(이하 B-box)와 confidence score를 계산하는데, 여기서 confidence score는 B-box 내에 객체가 해당 경계 상자에 있을 확률과 그 B-box가 실제 객체와 얼마나 잘 맞아 떨어지는 지를 나타낸다.
- Confidence Score: $PR(Object) * IOU^{truth}_{pred}$
- $PR(Object):$ grid cell 내부에 물체가 존재할 확률
- $IOU^{truth}_{pred}:$ Ground Truth와 B-box가 겹치는 정도
- cell 내부에 물체가 없다면 이는 0이된다.($PR(Object)=0$) 그렇지 않다면 IOU에 따라 값이 결정됨
- 목표는 confidence score가 Ground Truth의 IOU와 동일한 값을 갖게 하는 것이다.
- Conditional Class Probabilities: $Pr(Classi |Object)$
- 특정 grid cell 내에 객체가 있을 때, 이것이 특정 클래스에 속할 확률
- 하나의 grid cell은 속한 B-box의 수에 관계없이 하나의 클래스에 대한 확률만을 계산함
- Confidence Score: $PR(Object) * IOU^{truth}_{pred}$
2.1 Network Design
- 1 x 1 Conv 레이어를 통해서 필터 차원을 축소하는 기법을 사용함 이를 통하여 파라미터 수를 줄이는 식으로 사용
- ex) (110 x 110 x 192) 인풋 데이터를 채널 수 128의 (1 x 1) conv 레이어를 거치면 (110 x 110 x 128) 차원으로 변경됨.
2.2 Training
- B-box의 크기를 이미지의 높이와 너비에 대해서 normalized하여 0~1 사이의 값을 갖게함
- B-box의 중심$(x,y)$는 해당 box가 포함되는 grid cell을 기준으로 상대적으로 표현된다. 좌상단이 (0,0), 우하단이 (1,1)로 표현된다. 만일 box의 중심이 어떠한 grid cell의 우측 하단에 위치한다면 (0.8, 0.7)과 같이 표현된다.
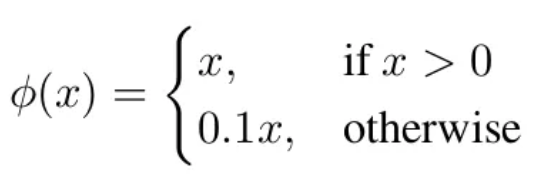
- Activation Function으로는 Leaky ReLU가 사용됨
- Loss Function으로는 sum-squared error를 사용하였으나 이는 객체 탐지에서 중요한 여러 유형의 오류(예: 경계 상자(localization) 오류와 분류(classification) 오류)를 같은 비중으로 다루기에 결과적으로 이는 최적화의 초점이 잘못 맞춰질 수 있는 문제를 야기함
- 이미지의 grid cell의 대부분에는 물체가 존재하지 않는다. 이는 대부분의 grid cell의 confidence score가 0이 됨을 의미하는데, 결국 객체가 없는 셀의 손실이 학습에 더 큰 영향을 주게 된다.
- 이를 위해 두 개의 안정화 파라미터 $λ_{coord}=5$ , $λ_{noobj}=0.5$를 도입함.
- $λ_{coord}=5$: 경계 상자 좌표 예측의 Loss를 더 중요하게 취급하기 위해 경계 상자 관련 Loss에 5배의 가중치를 부여
- $λ_{noobj}=0.5$: 객체가 없는 셀에서의 신뢰도 손실을 줄이기 위해 가중치를 0.5배로 설정
- 큰 B-box와 작은 B-box 사이에서의 Loss의 경우에도 동일한 비중으로 처리되는데, 일반적으로 작은 B-box에서의 좌표 변화가 큰 B-box에서의 좌표 변화보다 큰 영향을 미치므로 B-box의 (w,h)에 대해서 제곱근을 적용한 값을 예측하도록 학습함.

- 좌표 손실 (Localization Loss) - 경계 상자의 중심 (x, y)
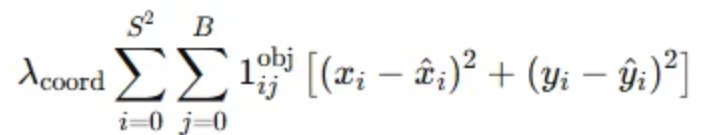
- 목적: 경계 상자의 중심 좌표 x와 y의 예측 값과 실제 값의 차이를 줄이는 것
- $λ_{coord}=5$로 설정하여 좌표에 대한 Loss가 학습에 많이 반영되도록 설정
- 좌표 손실(Localization Loss) - 경계 상자의 너비와 높이(w,h)
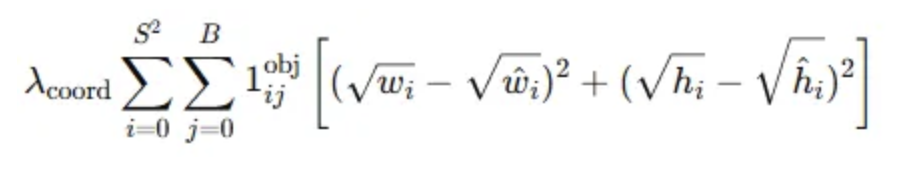
- 목적: w, h에 대한 손실을 줄이는 것
- w와 h에 제곱근을 적용하여 작은 B-box에서의 작은 변화가 큰 B-box에서의 작은 변화보다 크게 반영이 될 수 있도록 설정
- 객체 존재에 대한 신뢰도 손실 (Confidence Loss) - 객체가 있는 경우
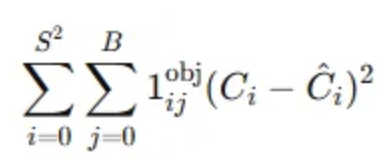
- $C_i:$ 예측된 경계 상자가 객체를 포함하고 있을 확률을 의미.
- $\hat{C}_i:$ 객체가 존재하면 1, 존재하지 않으면 0
- 객체가 없는 셀에 대한 신뢰도 손실 (Confidence Loss) - 객체가 없는 경우
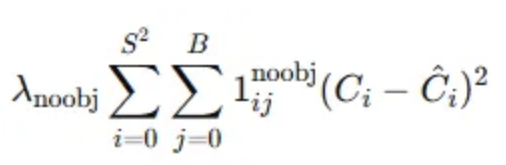
- $λ_{noobj}=0.5$로 설정하여 객체가 없는 셀에 대해서는 학습에 적은 영향을 미치도록 설정함
- $1^{noobj}_{ij}:$ 객체가 없는 경우에만 활성화됨
- 클래스 확률 손실 (Classification Loss)
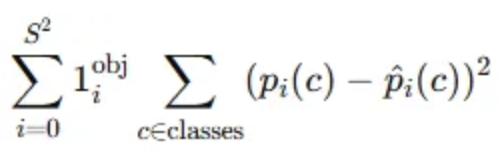
- 실제 클래스와 예측 클래스 비교
- $p_{i}(c):$ i번 grid cell에서 예측한 클래스 c의 확률.
- $\hat{p}_{i}(c):$ 실제 클래스 c의 확률 (0 또는 1)
- $1^{obj}_{ij}:$ 객체가 있는 경우에만 클래스 확률 loss를 계산
- Dataset: Pascal VOC 2007 / 2012
- batch size =64, momentum = 0.9, decay = 0.0005로 학습함. 총 135 에포크
- 첫 에포크에서 learning rate를 1e-3에서 1e-2로 서서히 올림. 75 에포크 까지 1e-2로 학습
- 추후 30 에포크는 1e-3으로, 나머지는 1e-4로 학습
- 과적합 방지를 위해 첫 connected layer 뒤에 0.5의 drop out을 적용
2.3 Inference
non-maximal suppression
- 큰 크기등으로 인하여 여러 셀에 걸쳐있는 객체의 경우 여러 개의 B-box가 하나의 객체를 탐지할 수 있다. 이로 인해 중복 탐지가 발생할 수 있는데, 이를 (non-maximal suppression, 이하 NMS)를 통해서 해결함.
- 여러 B-box가 동일한 객체를 탐지한 경우 가장 Confidence Score가 높은 box 하나만을 선택하고 나머지는 제거함
- 이로 인해 mAP가 2~3% 정도 개선됨
2.4 Limitation of YOLO
- 고정된 수의 B-box를 가지고 있어 비정상적으로 긴 객체나 작은 객체와 같은 다양한 형태의 객체 탐지에 어려움
4.2 VOC 2007 Error Analysis
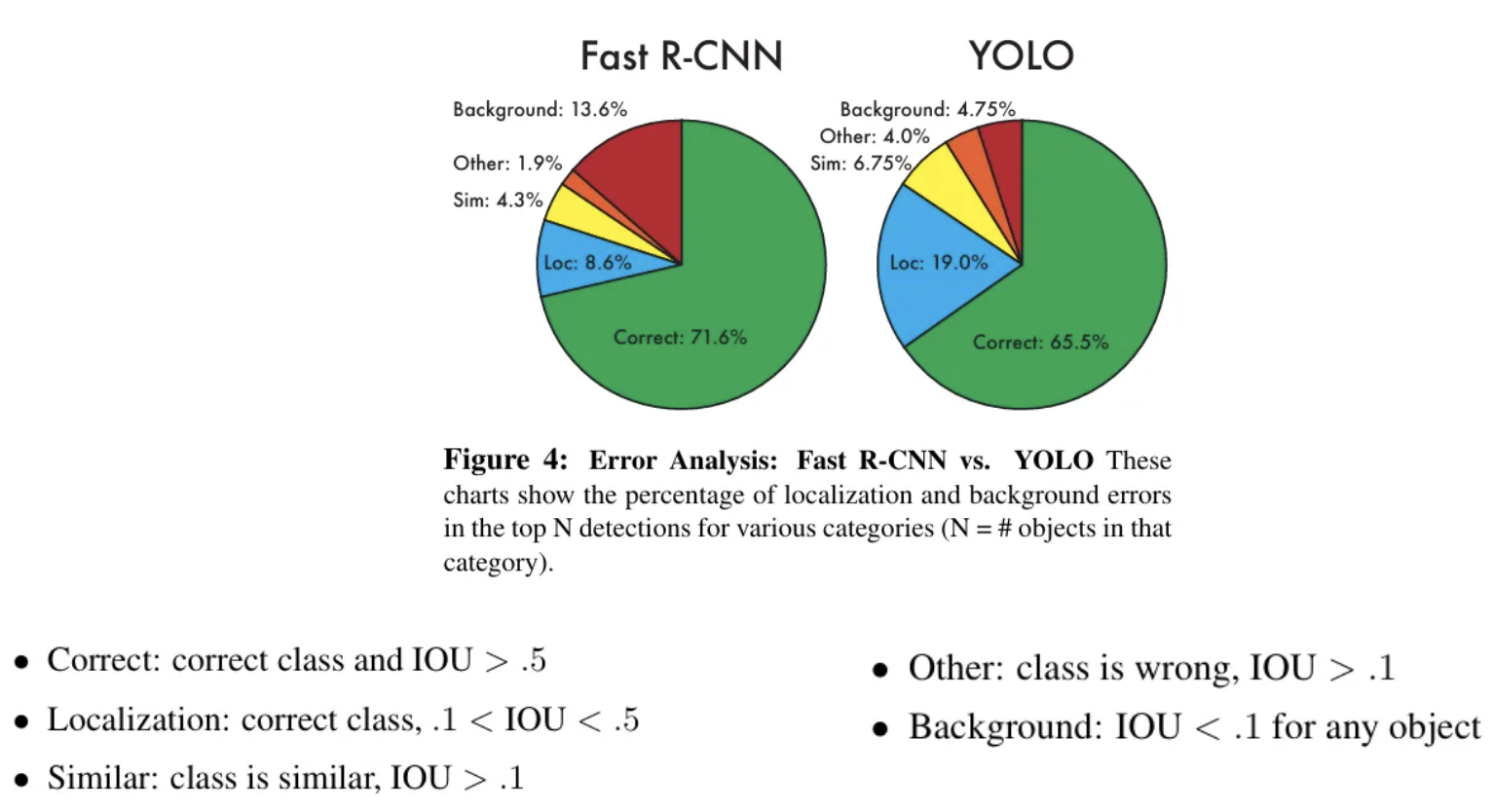
- 배경 탐지나 클래스 비교에서는 좋은 성능을 보여주나, 물체의 위치 탐지에서는 부족한 모습을 보여줌
'AI' 카테고리의 다른 글
| 논문- ImageNet Classification with Deep ConvolutionalNeural Networks (1) | 2024.10.09 |
|---|---|
| 논문리뷰- A Survey on Antispoofing Schemes for Fingerprint Recognition Systems (0) | 2024.09.06 |
| RNN (0) | 2024.08.25 |
| CNN (0) | 2024.08.25 |
| Activation function과 Weight initialization (0) | 2024.08.22 |



